友情链接:

AIPress.com.cn报谈
腾讯混元盘考团队近日在官方博客发布最新盘考后果,围绕大模子强化学习中的工程瓶颈问题伸开系统性探索。这是继此前发布《Learningfromcontextisharderthanwethought》之后的第二篇公开盘考。团队这次聚焦于可考证奖励强化学习(RLVR)锻真金不怕火中的可不雅测性问题,尝试通过基础才略级器具责备底层机理盘考的工程门槛。
频年来,大模子竞争重点已从预锻真金不怕火阶段迟缓转向后锻真金不怕火优化。借助数学、代码等具备可考证握法的响应信号,RLVR成为普及模子推理才略的迫切旅途。联系词,与相对纯熟的预锻真金不怕火工程体系比较,大界限RLVR锻真金不怕火在着力压力下引入了多半肖似诡计,使得系统演变为一个高噪声、强耦合的复杂动态系统。数据散播与模子参数互相影响,眇小过错在迭代中被放大,导致锻真金不怕火动态难以分析,底层机理盘考经常受限于工程可不雅测才略。
在这一配景下,腾讯混元团队推出相配梯度定位器GradLoc(GradientAnomalyLocalizer),标的是将全局层面的“梯度突刺”(GradientSpike)风雅目位至具体相配Token。该器具已在TencentHunyuan官方博客公布,并在GitHub开源。
锻真金不怕火崩溃是RLVR实施中的常见挑战,频繁表现为模子准确率骤降,并随同梯度范数相配波动。在传统排查经由中,盘考东谈主员只可依据全局测度打算如grad_norm弧线进行领导推断,再通过端到端本质考证假定,过程高度依赖个东谈主领导,考证周期长回去因朦拢。GradLoc则将问题颗粒度从“全局”鼓吹至“微不雅”,通过定位相配Token,为工程排查提供径直字据。
技巧达成上,GradLoc针对散播式锻真金不怕火环境进行深度适配,引入二分搜索计谋,将相配定位复杂度由线性级责备至对数级。系统在全局Batch、Micro-Batch、诡计节点(Rank)与Token等不同层级间逐级平缓范围,快速锁定相配起原。为普及着力,GradLoc领受诡计式深度优先搜索计谋,乐鱼优先跟踪梯度范数较大的分支,在险些不加多稀薄耗时的情况下定位多个相配Token。同期,器具鸠合梯度向量统计特质联想自适合阈值机制,以责备误检与漏检风险。
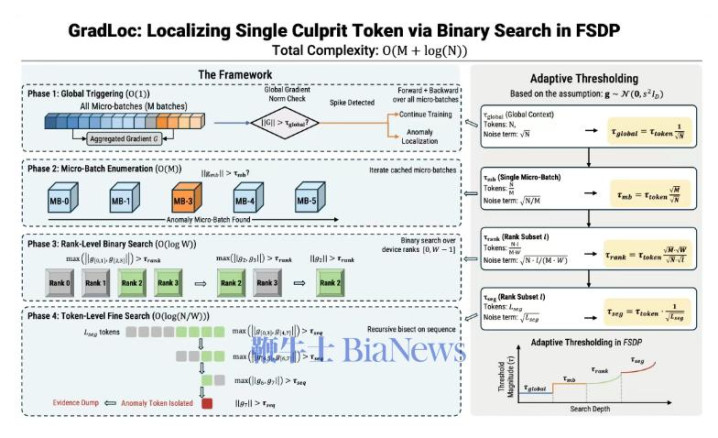
在性能支出方面,GradLoc仅在检测到梯度突刺时触发,属于“常驻待命”形态。团队透露的数据标明,相配Step的耗时会加多约1至3倍,但在长周期锻真金不怕火中全体摊销老本较低。

在具体运用中,团队以Qwen3-4B-Instruct模子为本质对象,从范例GRPO算法启程,借助GradLoc迟缓排查导致锻真金不怕火崩溃的身分。定位握法浮现,相配起原包括Token级锻真金不怕火与推理不一致、序列级锻真金不怕火与推理不一致以及层间梯度异质性。针对不同类别问题,团队折柳引入TokenClip、SeqClip与LayerClip进行干涉,锻真金不怕火厚实性获得迟缓普及。
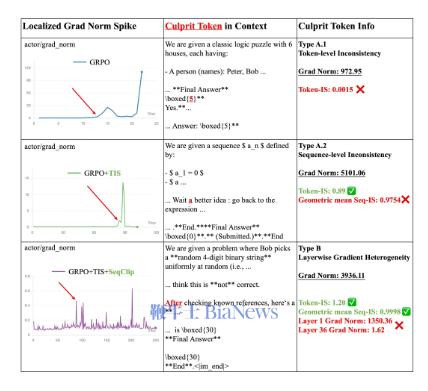
盘考团队暗示,GradLoc的中枢价值并非单一算法改良,而在于构建一套可研讨、可范例化的相配排查基础才略。通过将“锻真金不怕火失败”精准映射到具体Token及层级结构,排查周期可由以往的数周裁汰至数小时,从而普及算法迭代着力。
同期,团队合计,GradLoc揭示的“层间梯度异质性”时局可能指向尚未充分知道的锻真金不怕火能源学机制。刻下冷漠的LayerClip更多属于缓解技巧,尚未从根蒂上讲明该时局。翌日盘考将进一步探讨有关物理与统计机理,以期从优化表面层面普及大模子强化学习的厚实性与着力。
在强化学习迟缓成为大模子才略跃升关键旅途的配景下,如何责备工程门槛、普及锻真金不怕火动态可不雅测性,已成为产业与学界共同关心的议题。腾讯混元这次发布的GradLoc器具,尝试坚决化学习调优从依赖领导的“黑盒”过程,转向更具可讲明性和可会诊性的工程体系。